menno
-
Items
2.190 -
Registratiedatum
Alles dat geplaatst werd door menno
-
De script-stap Re-Login[] is alles wat je nodig hebt. Zie http://www.filemaker.com/help/html/scripts_ref2.37.33.html
-

gebruikersnaam en inlogcode automatisch invullen
menno reageerde op Gerard Exis's vraag in FileMaker 12
Is de beveiliging van de website geregeld met htaccess dan werkt het voorbeeld van Felix inderdaad prima, maar log je in via een formulier (en dat is bij joomla, magento, wordpress, drupal etc. het geval) dan zal dat niet werken, maar daar is dat vaak ook helemaal niet nodig. Ik gebruik zelf bij een klant een webviewer om met een Wordpress-site te communiceren en hebben we gewoon de inlog bewaard (vinkje ingelogd blijven aan én wachtwoord opgeslagen), één keer opgegeven en voortaan zonder tussenstap inloggen (tenzij je je afmeld). -
PDF is geen volledige afdrukweergave, velden verdwijnen
menno reageerde op SuperWimmie's vraag in FileMaker 13
Gebruik je misschien vaste pagina-marges van 0 pixels en blijf je dan zelf maar ver genoeg van de randen weg? Ik heb zoiets dergelijks ook eens gehad en door de marge door de (pdf-)printer te laten bepalen was het probleem verdwenen. Wordt natuurlijk wel lastig als er meerdere typen en merken printers worden gebruikt, maar je kan het even proberen -
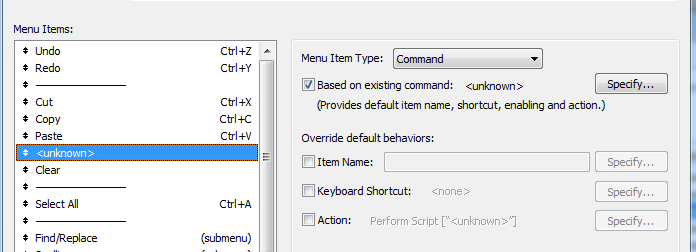
Het is zelf zo dat wanneer je op de mac alle standaard menu's overneemt en op windows dat menu gaat bewerken dat je krijgt te zien op de plek van de menukeuze: Het is overigens wél de énige optie waar dit mee gebeurt, dus ze zullen het inderdaad zijn vergeten. Standaard kan je in Filemaker op Windows plakken zonder opmaak door de shift-toets ingedrukt te houden. Als je je eigen-menus maakt kan je daar rekening mee houden.

-
Is de waarde in de kolom jrmd misschien een getal? Dan horen de single-quotes niet in BETWEEN '201401' AND '201406' Ik heb zoiets nog niet geprobeerd met een geneste query in een JOIN-declaratie, maar wel met de IN-clausule en als je dan bijvoorbeeld: SELECT kolom FROM tabel WHERE anderekolom IN ( SELECT kolom FROM anderetabel WHERE etcetc ) doet, dan heeft Filemaker daar erg veel moeite mee. Wijzig je dit in 2 aparte queries: hulpresultaat = SELECT kolom FROM anderetabel WHERE etcetc eindresultaat = SELECT kolom FROM tabel WHERE anderekolom IN ( hulpresultaat ) dan krijg je het resultaat in een fractie van de tijd terug. Kortom FM houdt van eenvoudige recht toe, recht aan queries.
-
Hi Erez, bel me even, dan kunnen we overleggen. Jos heeft mijn nummer.
-
Nee ik denk dat het quotum op de server gewoon bereikt is. Ik had gisteren hetzelfde probleem en heb vervolgens enkele plaatjes uit een héél oud bericht verwijderd en dat leverde weer 250kb ruimte op die ik meteen heb gebruikt om een bestandje te uploaden. Peter zal ofwel wat ruimte moeten moeten maken of de directory voor de uploads op een grotere schijf moeten onderbrengen, maar dat zal wel even tijd kosten gok ik.
-
Dat is gewoon een extra weergave van een tabel ( Table-Occurrence ). Daarvan kan je er bij wijze van spreken oneindig veel gebruiken zonder dat de hoeveelheid data wordt beïnvloed.
-
Welke versie van Ms-Office wordt er gebruikt? Ik heb het getest met 2013/365 en dat werkt op 2008R2 en op 8.1 zonder problemen. linefeed en alineafeed komen beide enkele returns in FM en ook de tabs komen als tabs over. zit werkelijk op W2K8R2 te werken of via RDP en indien dat laatste, waarvanaf? WXP, W7, W8, MacOS. Wat zijn dan de lokale toetsenbord/taal instellingen etc etc.?
-
Separate data format op server: wat met accounts?
menno reageerde op LcGrs's vraag in FileMaker Server 13
En zo is het maar net, wat voor mij perfect werkt hoeft voor een ander helemaal niet de juiste weg te zijn. -
Met een global GTRR en een scripttrigger lukt het prima: Toon_in_lijst.fmp12
-
Soms zijn de wonderen de wereld niet uit ...
menno reageerde op Stardust's vraag in FileMaker Server 13
En daarom is het goed dat Filemaker zich nu een stuk duidelijker profileert als "An Apple Subsidiary", misschien dat Apple wat meer (sluik-)reklame moet gaan maken voor FMI. De sleutel is de naamsbekendheid, dan neemt de interesse vanzelf toe en daarmee de acceptatie -
Knop Zoekopdracht uitvoeren niet actief
menno reageerde op BaW01's vraag in FileMaker Pro 12 Advanced
De gebruiker kan wel naar zoekmodus en een zoekopdracht definiëren, maar niet uitvoeren, want dat heb je onmogelijk gemaakt door die opdracht uit het menu te verwijderen. De eenvoudigste 2 manieren op dit op te lossen zijn: De opdracht "zoeken uitvoeren" weer beschikbaar maken in het menu "verzoeken", zodat de gebruiker op "enter" kan drukken om de zoekopdracht uit te voeren. Maak een script met "zoeken uitvoeren" en dat koppel je aan een knop op de layout. -
Separate data format op server: wat met accounts?
menno reageerde op LcGrs's vraag in FileMaker Server 13
@ HE: Correct, de relaties zijn one-way-only en het is inderdaad een hybryde oplossing. Het doel ervan is dat je alleen maakt wat je voor een specifiek doel nodig hebt. In mijn optiek hebben invoer, uitvoer en rapportage bijvoorbeeld alleen maar de data als gemeenschappelijke factor, maar zouden ze elkaar in de weg zitten en dus heb ik het uit elkaar gelaten. -
De crash met GTRR beschouw ik als een symptoom, want ik bedoel eigenlijk dat er iets raars is met het evalueren van de waarden in globals door FM. In het ene geval werkt het aanpassen van de global-waarde zonder commit meteen door als in het tonen van records in een portal. In datzelfde geval werkt een knop in die gerelateerde records waarmee je GTRR uitvoert niet (en crasht FM zelfs!), terwijl dat wel zou werken als je een commit zou doen vóór de GTRR. Exact hetzelfde lijkt het probleem als ik een global gebruik om een record te "ontgrendelen", dat werkt ook pas nádat er een commit is uitgevoerd (overigens is dit niet alleen in FM13 een probleem, dat was voorheen ook al zo in FM12 en FM11).
-
Separate data format op server: wat met accounts?
menno reageerde op LcGrs's vraag in FileMaker Server 13
Zoveel ontwikkelaars ... zoveel meningen. Ik ontwikkel nu alweer enkele jaren bij nieuwe projecten met data en interface gescheiden en heb veel oude projecten waarbij dat niet werd gedaan en veel van de oude projecten hebben ook nog eens veel bestanden. Deze projecten worden alleen niet alleen door mij bediend, maar ook mijn collega's werken er af en toe en soms regelmatig aan en ik kan het denk ik zelf inmiddels aardig met elkaar vergelijken. Een dataseparatie-model heeft voor- en nadelen, maar die moet je genuanceerd zien, want véél accounts hoeft geen probleem te zijn en véél bestanden ook niet. Ieder heeft daarbij ook zijn smaak misschien wel ontwikkeld. Onze projecten zijn zonder uitzondering in een multi-user-omgeving en waarbij er een beperkt aantal soorten users zijn. De klanten wisselen per dag hun eisen over de privileges die medewerkers in hun systemen hebben en willen dat het liefst zelf kunnen controleren en aanpassen. Als ontwikkelaar wordt van mij verwacht dat ik een zekere data-integriteit afdwing, waarbij een directeur wél bepaalde gegevens mag wijzigen en de ene manager mag dat ook, maar de andere weer niet en een gewone kantoormedewerker mag het alleen maar zien oid. Als je dit gaat proberen op te lossen door de FM-privilege-instellingen uitgebreid toe te passen, dan wordt zoiets al snel niet onderhoudbaar, laat staan overdraagbaar. Ik werk eigenlijk alleen maar met een zeer beperkte set met 3 privilege-sets en 3 accounts: De "admin", de "user", de "kijker", waarbij de user en de kijker veel lijken op [data-entry only] en de [read-only], maar wel eigen privilege-sets zijn. Dat is gemakkelijk te repliceren naar andere bestanden als je meerdere bestanden hebt. Alle bestanden die geen deel uitmaken van de "interface" zijn voor iedereen die geen admin is gewoon "dicht" als dat nodig is en soms moet er wel iets "open" staan voor bijvoorbeeld onderhoud en dat kan je dan gewoon mogelijk maken/toevoegen. Er zijn voor de gebruikers records aangemaakt en daaraan gekoppeld zijn er privilege-records voor ieder losse privilege, adhv die records wordt hun toegang geregeld met enkele standaard scripts, waar alleen maar enkele parameters worden heengestuurd. Dat lijkt complex, maar is peanuts tov privileges in alle bestanden en bij iedere tabel in te moeten stellen, die je dan ook nog eens onderhouden. Over wat nou het voordeel is van separatie kan ik kort zijn: geen conversies meer. Okee soms moet je in de achterliggende model iets toevoegen en daar zijn uiteraard wel een paar aandachtspunten, maar dat komt beslist niet dagelijks voor. Het voordeel dat je een systeem platgooit, de interface uitwisselt en je start alles weer is voor veel bedrijven een positief argument. Tijdens de middagpauze geef je het hele bedrijf een aangepaste interface. Mijn favoriete model is Data (de CRM, ERP gegevens) Constanten (keuzelijsten, gebruikers, privileges, instellingen) Media Koppelbestanden (boekhouding, website, mailing-deamon) Uitvoer (dit zou ook in het inteface-bestand kunnen) Overzichten (kan ook in interface) Interface (eventueel voor iedere soort (i-device, desktop, server) een apart bestand) Ik zeg niet dat dit eenvoudig is, maar een volledig geïntegreerd systeem is minstens net zo complex. Als je echter de moeite hebt gedaan om een systeem op deze manier op te zetten, dan pluk je daar op termijn beslist de vruchten van. Het argument dat je je data-model op meerdere plekken moet nabouwen is niet helemaal correct. Het grootste deel van je model heb je nodig voor weergave voor de gebruiker om de data te kunnen beoordelen en bewerken. In een data-bestand hoeft alleen het hoogst noodzakelijke te staan zoals een header-regel-relatie om bijvoorbeeld snel de regels bij een offerte te verwijderen, maar doe je daar niet aan dan is zo'n relatie ook niet nodig. -
Er is iets vreemds aan de hand met die globals en commit-en in FM. Als je een global gebruikt als basis van een relatie, dan is het voldoende om de global in te stellen en het veld te verlaten (zonder het record vast te leggen) en dan werkt die relatie in die zin dat een portal op basis van die relatie meteen records gaat tonen. Wil je echter op basis van die global iets berekenen (in een veld), dan moet je het record wél vastleggen, anders werkt de berekening gewoon niet. Het lijkt er hier op dat GTRR ook moet worden beschouwd als een berekening, maar dat FM er op crasht, dat vind ik toch wel een bug. Ik gebruik zelf globals wel eens om vastgelegde records (als in: die mogen niet meer worden gewijzigd) te "ontgrendelen", door met de "eigen privileges" van de records te kijken naar een global waar een 1 in moet staan, wanneer een record tóch moet kunnen worden gewijzigd en dat werkt alleen maar na een commit.
-
Nee een BLOB is binaire data en BASE64 is tekst, dus zo werkt dat niet. Je zou als je een image in MySQL zou willen opslaan gerust BASE64 in een tekstkolom kunnen gebruiken en die weer terug om kunnen zetten als je het uitleest FM. FM legt zelf via ODBC queries de ESS-koppelingen, dus die queries zullen wel beperkt moeten blijven qua grootte en daarmee zal ook een image niet heel groot mogen zijn, hoe groot weet ik niet.
-
Hi Marseau, je bent zelf al een flink eind gekomen. Er zitten maar 3 foutjes in jouw xslt waardoor het niet werkt: De stylesheet-declaratie is onvolledig, het element is niet gesloten met ">" (moet komen voor: Waarden moet je selecten met " In xml moet je gewone "quotes" gebruiken en in jouw xslt staan op een aantal plaatsen "smart-quotes" en die worden niet begrepen er staat nu bijvoorbeeld “TIME” ipv "TIME" De aangepaste stylesheet wordt dan: <?xml version='1.0' encoding='UTF-8'?> 0 Ik weet niet of je vaak met xml/xslt aan de gang wilt, maar zo ja dan is het zinvol om een goeie xml-editor aan te schaffen, In zo'n editor zit ook een xslt debugger en daar los je dit soort problemen in 5 minuten mee op.
-
Het enige dat je bij dit soort problemen moet doen is voor jezelf in stappen duidelijk maken wát je precies probeert te doen en je vooral niet laten beperken door genomen stappen uit het verleden. Dat natuurlijk altijd nog opduiken, maar je kan het beste starten met te doen alsof dat niet zo is. Je zal mijn oplossing misschien niet zomaar kunnen implementeren in de db-sctructuur die je al hebt, maar het gaat om het idee en wellicht kan je de bestanden structuur zo aanpassen dat je het kan gebruiken. De kern van mijn suggestie is uitgegaan van de door jou beschreven excel. Het kan zijn dat er nog meer kolommen in staan, zoals een naam en een datum en andere informatie. Je zal dan de import moeten aanpassen om jouw situatie te accomoderen, maar het principe blijft overeind: je importeert de antwoorden in met nummers geïndexeerde veld(nam)en f1...fn zodat je later in een lus van die structuur gebruik kan maken met een oplopend tellertje etc. etc. en dat is dus anders dan de structuur van jouw gegevens. Je moet dus "out of the box" denken eigenlijk, maar vooral zo simpel mogelijk. Laat je ook vooral niet beperken door het feit dat je niet alle commando's van je software (in dit geval Filemaker) kent, maar bedenk gewoon de stappen die je wilt doen, bijvoorbeeld: Importeren Uit elkaar halen Wegschrijven voor een respondent Rapporteren en die stappen kan je ook weer verfijnen, daarna ge je het gewoon programmeren (en de juiste stappen en commando's erbij zoeken) Gebruik je filemaker 13 of 13 Advanced? Je kan om dit goed te ontwikkelen eigenlijk niet zonder script-debugger en gegevens-inzage. Het wordt anders best lastig om scripts zoals dit import-script goed op te zetten en te debuggen met het gebruik van variabelen en zo, want ipv de gegevens-inzage moet je dan tijdelijk waarden in global-fields gaan zetten en escapes in je script inbouwen waarmee je kan kijken wat er met je db gebeurt tijdens de uitvoer. Het is wel te doen hoor, want pre-FM6 hadden wij FM-ontwikkelaars geen debugger en geen gegevens-inzage en gegeven-inzage kregen we pas met FM7 en variabelen pas sinds FM8, maar het is allemaal véél ingewikkelder .... dus als je het nog niet gebruikt, stap dan over op Filemaker Pro Advanced, het is het extra geld beslist waard
-
Ik vind jouw probleem wel grappig dus heb ik even een excel-bestandje (antwoorden.xlsx) gemaakt met 4 rijen met 120 kolommen met antwoorden, dat in het fm-bestand "Vraag_maar_met_import.fmp12" kan worden geïmporteerd. Dat laatste bestand is identiek aan die van de vorige post, maar bevat 1 extra tabel waarmee alleen maar de excel wordt geïmporteerd. De werking: druk op de knop in de layout respondent en wijs het bestand "antwoorden.xlsx" aan en klik op importeer, that's it. De antwoorden worden in tijdelijke records geïmporteerd, met een lusje worden van ieder record van ieder veld variabelen gemaakt. Vervolgens wordt er een respondent-record aangemaakt en worden er vanuit de vragen-tabel 120 antwoord-record voor de nieuw aangemaakte respondent geïmporteerd. De volgende stap vult alle antwoorden in die in de variabelen zijn opgeslagen en dat gaat door totdat alle tijdelijk antwoord-records zijn verwerkt. Daarna worden alle tijdelijke records verwijderd en het script eindigt op de layout waar je was begonnen. Kijk in het script voor de uitleg, want er komen aardig wat filemaker-technieken bij kijken: (Sub-)Scripting Fout-afvanging Importeren uit excel If-functie Get-functie Programmalussen Evaluate-functie Variabelen instellen Variabelen maken met evaluate/let Velden vullen met variabelen Archief.zip
-
Als je het dynamisch wilt houden dan is het niet handig om 120 antwoorden op één record te hebben. Dat kan je beter (zoals in het voorbeeld van Ruben) opsplitsen in één antwoord per record (en per respondent uiteraard). Zoals jij het nu hebt opgezet is het vind ik een statisch geheel. Bijgaand een bestand het een en andere wél dynamisch is opgebouwd. Op de layout respondent staat een portaal met de vragen. Iedere keer dat je een nieuwe respondent aanmaakt, wordt er in de tabel antwoord een import van alle vragen gedaan. De vragen zijn gekoppeld aan een categorie, zodat aan iedere vraag een gewicht is gekoppeld wat je kan resumeren. Het resultaat kan je zien op de layout antwoord, door het script "Toon antwoordoverzicht" te draaien .... die gaat naar de layout, toont alle records en sorteert ze vervolgens. Vraag_maar.fmp12
-
Maak in de tabel antwoordenlijst een resumé-veld aan met het totaal van het resultaat. Maak op je rapportagelayout 2 subresumé's 1 met sortering op respondent en 1 met sortering op categorie en plaats in beide subresumé's het zojuist gemaakte resumé-veld Sorteer nu op respondenten en daarbinnen op categorie
-
geen commentaar meer
-
Je wilt dus een tekst met daarin een berekende tijdsaanduiding weergeven? Dat betekent tijd weergeven als tekst en als je aantal minuten (maar dat geldt ook voor seconden en eventueel uren) uit een getal van < 10 bestaat, dan heb je een "voorloop"-0 nodig. Een volledige tijd als tekst kan je dan als volgt weergeven: Right ( "0" & uren ; 2 ) & ":" & Right ( "0" & minuten ; 2 ) & ":" & Right ( "0" & seconden ; 2 ) en dan kan je een tijd wel weergeven als 00:05:07 ipv 0:5:7 of zoals jij het berekent: Right ( "0" & Hour ( Werkbonnen::begintijd ) ; 2 ) & ":" & Right ( "0" & Minute ( Werkbonnen::begintijd ) ; 2 )